我們擅長商業策略與用戶體驗的完美結合。
歡迎瀏覽我們的案例。
在自然語言處理領域,常用語言模型(LMs)可以實現為字符(tokens)序列分配概率。
最近,LMs 還在對編程語言編寫的源代碼進行建模方面表現出強大的性能,擅長從自然語言描述中完成和生成代碼。
在基于人工智能的編程支持下,目前最先進的大型語言模型的編寫代碼能力已經有了巨大改進。
AI 自動寫代碼的潛力
代碼生成 AI 模型的好處是顯而易見的,它可以降低開發成本,同時允許編碼人員專注于創造性的、重復性較低的任務。也正因如此,越來越多的組織正在探索代碼生成人工智能。
Codex 是其中之一。它是 OpenAI 推出的新的深度學習驅動平臺,可自動編寫能夠正常工作的軟件代碼。該系統以大量公開代碼作為語料庫進行了訓練,是 GitHub Copilot 上的一個功能,可幫助程序員自動改進或更新軟件。
DeepMind 出品的 AlphaCode 也是最早與人類程序員競爭的代碼生成系統之一。編程競賽平臺 Codeforces 上舉辦的編程競賽中,DeepMind 表示,與 5000 多名程序員競爭,AlphaCode 的平均排名在前 54.3% 之內。
目前,OpenAI 和 Alphabet 支持的 DeepMind 等機構已經開發出強大的代碼生成 AI,但這些最強大的系統并沒有開源。例如,Codex 只允許在收費情況下,通過黑箱 API 調用模型的輸出,但不允許訪問模型的權重或訓練數據。
也就是說,盡管語言模型在編碼方面取得了巨大的成功,但由于性能最好的語言模型沒有開源,這就限制了資源缺乏的公司在該領域的研究,例如,研究人員無法對模型進行微調在源代碼實現之外的任務或領域中使用。而且無法訪問模型的內部結構也限制了研究人員研究模型的其他重要特性,例如可解釋性、為了實現高效應用的模型蒸餾,以及引入檢索等額外功能。
GPTNeo、GPT-J 和 GPT-NeoX 是三種公開可用的預訓練語言模型,其規模涵蓋中等到大型。通過在新聞文章、互聯網論壇和少數(GitHub)軟件庫等大量數據上進行訓練,這些語言模型能夠以較快的速度生成源代碼。另外還有一些僅在源代碼上訓練的開源語言模型,例如 CodeParrot 模型是在 180 GB 大小的 Python 代碼上訓練的。
由于這些模型的大小和訓練策略各不相同,而且沒有完善的實驗比較,還不清楚建模方法和訓練策略對語言模型的影響。
例如,我們無法知道 Codex 和其他自用模型訓練使用的實際數據集。而且一些開源模型是在大量自然語言和代碼上進行訓練,而另一些(例如 CodeParrot)則只在一種編程語言的代碼上訓練。
不過,使用不同編程語言中相似的關鍵字和特征,使得多語言模型的泛化能力較強,這一點在多語言模型的實際使用中得到證明。也就是說,多語言 LMs 具有跨語言使用、優于單語言模型的優點。
PolyCoder 問世
最近,卡內基梅隆大學(Carnegie Mellon University)的研究人員發表了一篇論文 A SYSTEMATIC EVALUATION OF LARGE LANGUAGE MODELS OF CODE ,對比了現有的跨編程語言的編寫代碼模型——Codex、GPT-J、GPT-Neo、GPT-NeoX 和 CodeParrot。通過對多個模型的比較和分析,這個團隊希望為代碼建模設計決策提供更多啟發。

他們首次證明了,大型的開源語言模型都不僅僅在幾種編程語言的代碼上進行訓練。
這篇論文中,他們還提出一個基于 OpenAI 的GPT-2語言模型的模型PolyCoder。該模型在包含 249 GB 代碼的數據庫上進行了 12 個編程語言。
雖然 PolyCoder 在每項任務中都無法與頂級代碼生成器的性能相媲美,但研究人員聲稱,PolyCoder 能夠以比所有已知模型更高的準確度用 C 語言編寫,包括 Codex 在內。
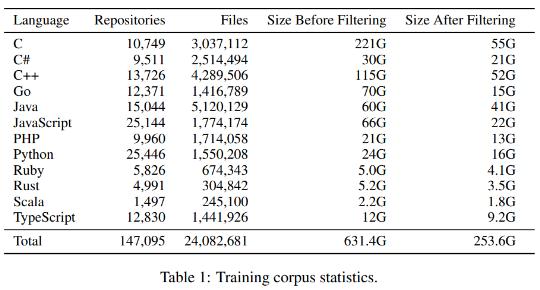
首先,該團隊對 PolyCoder、開源模型和 Codex 的訓練和測試設置進行對比研究。
其次,使用 HumanEval 基準研究各種模型大小、訓練步驟,以及不同的溫度對模型生成代碼質量的影響。
最后,由于 HumanEval 只能評估自然語言到 Python 語言的生成結果,所以他們創建了一個 12 種語言的測試數據集,用來評估各種模型的性能。
研究人員發現,盡管 Codex 模型表面上只能處理 Python 語言,但它在其他編程語言中的表現也很不錯,超過了在 Pile 上訓練的 GPT-J 和 GPT-NeoX 模型。但是在 C 語言中,PolyCoder 模型的性能比其他所有模型(包括 Codex)的都好。
而且在 C、JavaScript、Rust、Scala 和 TypeScript 語言中,PolyCoder 比同樣大小的開源模型 GPT-Neo 2.7B 相比性能更好。
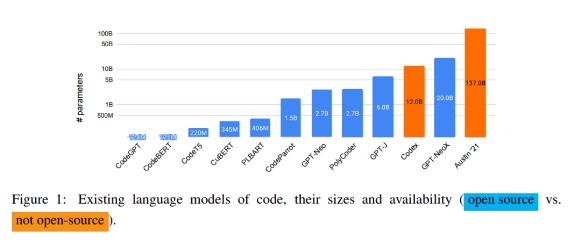
但在 C 語言之外的 11 種語言上,其他的開源模型,包括 Polycoder 的表現低于 Codex。這是因為 Polycoder 是在數據不平衡的混合語言上訓練的,而且 C++和 C 語言是有相關性、且在訓練語料中最普遍的兩種語言。所以 C 語言的數據量更大,PolyCoder 模型就認為 C 是“首選”的編程語言。但 C++語言更為復雜,并且 Codex 擁有更大的上下文窗口(4096 vs. PolyCoder 的 2048),或者因為 Codex 是在更多的 C++訓練數據上訓練出來的,所以導致 Codex 在 C++上的表現優于 PolyCoder。
總而言之,這項研究中研究人員對大量語言模型的編碼能力進行了全面實驗。一般來說,更大的模型和更多的訓練時間有利于提高模型性能。GPT-superior Neo 模型在某些語言中的性能表明,對自然語言文本和代碼的訓練有助于對代碼進行建模。
而 PolyCoder 則是用于編碼的大規模開源語言模型,在 12 種不同的編程語言代碼上訓練而得,它的發布有助于未來在該領域的研究。雖然 PolyCoder 在每項任務中的性能都無法與頂級代碼生成器相媲美,但研究人員聲稱,PolyCoder 能夠以比包括 Codex 在內的所有已知模型以更高的準確度用 C 語言編寫代碼。
(邯鄲微信平臺)