我們擅長商業策略與用戶體驗的完美結合。
歡迎瀏覽我們的案例。
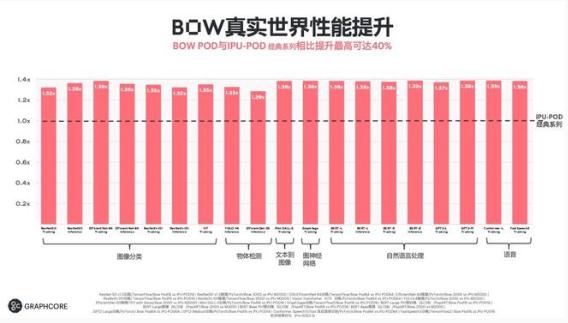
周四,英國的明星 AI 芯片公司 Graphcore 發布了一款 IPU 產品 Bow,采用臺積電 3D 封裝技術,性能提升 40% ,首次突破 7 納米工藝極限。
全球首顆 3D 封裝芯片誕生!
周四,總部位于英國的 AI 芯片公司 Graphcore 發布了一款 IPU 產品 Bow,采用的是臺積電 7 納米的 3D 封裝技術。
據介紹,這款處理器將計算機訓練神經網絡的速度提升 40%,同時能耗比提升了 16%。
600 億晶體管,首顆 3D 芯片誕生
能夠有如此大的提升,也是得益于臺積電的 3D WoW 硅晶圓堆疊技術,從而實現了性能和能耗比的全面提升。
正如剛剛所提到的,與 Graphcore 的上一代相比,Bow IPU 可以訓練關鍵的神經網絡,速度約為 40%,同時,效率也提升了 16%。
同時,在臺積電技術加持下,Bow IPU 單個封裝中的晶體管數量也達到了前所未有的新高度,擁有超過 600 億個晶體管。
官方介紹稱,Bow IPU 的變化是這顆芯片采用 3D 封裝,晶體管的規模有所增加,算力和吞吐量均得到提升,Bow 每秒可以執行 350 萬億 flop 的混合精度 AI 運算,是上代的 1.4 倍,吞吐量從 47.5TB 提高到了 65TB。
Knowles 將其稱為當今世界上性能最高的 AI 處理器,確實當之無愧。

Bow IPU 的誕生證明了芯片性能的提升并不一定要提升工藝,也可以升級封裝技術,向先進封裝轉移。
Graphcore 首席技術官和聯合創始人 Simon Knowles 表示,「我們正在進入一個先進封裝的時代。在這個時代,多個硅芯片將被封裝在一起,以彌補在不斷放緩的摩爾定律 (Moore’s Law) 道路上取得的不斷進步所帶來的性能優勢。」
臺積電真 WoW!
2018 年 4 月,在美國加州圣克拉拉舉行了第二十四屆年度技術研討會。在這次會上,全球最大的半導體代工企業臺積電首次對外公布了名叫 SoIC(System on Integrated Chips)的芯片 3D 封裝技術。
這是一種整合芯片的封裝技術,由臺積電和谷歌等公司共同測試開發。而谷歌也將成為臺積電 3D 封裝芯片的第一批客戶。
什么是封裝技術呢?
封裝技術的主要功能是完成電源分配、信號分配、散熱和保護等任務。而隨著芯片技術的不斷發展,推動著封裝技術也在不斷革新。
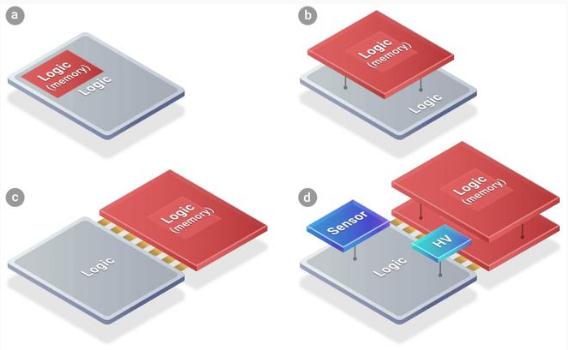
而 3D 封裝技術,簡單來說,就是指在不改變封裝體尺寸的前提下,在同一個封裝體內,在垂直方向上疊放兩個或者更多芯片的技術。
相較于傳統的封裝技術,3D 封裝縮小了尺寸、減輕了質量,還能以更快的速度運轉。
臺積電在年度技術研討會上表示,SoIC 是一種創新的多芯片堆疊技術,是一種晶圓對晶圓的鍵合技術。SoIC 的實現,是基于臺積電已有的晶圓基底芯片(CoWoS)封裝技術和多晶圓堆疊(WoW)封裝技術所開發的新一代封裝技術。
晶圓基底芯片(CoWoS),全稱叫 Chip-on-Wafer-on-Substrate,是一種將芯片、基底都封裝在一起的技術。封裝在晶圓層級上進行。這項技術隸屬于 2.5D 封裝技術。
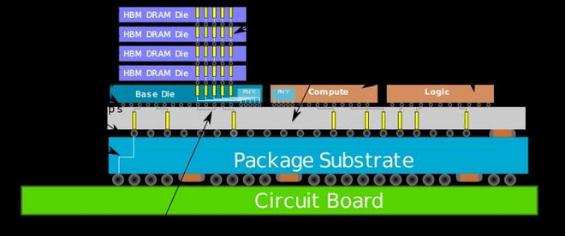
而多晶圓堆疊技術,或者堆疊晶圓(WoW,Wafer on Wafer),簡單來說,就是取代此前在晶圓上水平放置工作單元的技術,改為垂直放置兩個或以上的工作單元。這種做法可以使得在相同的面積下,有更多的工作單元被放到晶圓之中。
這樣做還有另一個好處:每個晶片可以以極高的速度和最小的延遲相互通信。甚至,制造商還可以用多晶圓堆疊的方式將兩個 GPU 放在一張卡上。
但也存在問題。晶圓被粘合在一起后,一榮俱榮、一損俱損。哪怕只有一個壞了,另一個沒壞,也只能把兩個都丟棄掉。因此,晶圓量產或成最大問題。
而為了降低成本,臺積電只在具有高成品率的生產節點使用這項技術,比如,臺積電的 16nm 工藝。
相較于 CoWoS 和 WoW,SoIC 更倚重 CoW(Chip on Wafer)設計。對于芯片業者來說,采用 CoW 設計的芯片,生產上會更加成熟,良率也可以提升。
值得一提的是,SoIC 能對小于等于 10nm 的制作過程進行晶圓級的鍵合。鍵合技術無疑會大大提高臺積電在這方面的競爭力。
練手怎么樣?
Bow 是 IPU-POD 人工智能計算系統的核心,稱為 BOW PODs。
它可以從 16 個 BOW 芯片擴展到 1024 個,提供高達 358.4 千億次的計算機運算速度,同時配合多達 64 個 CPU 處理器。
新的 Bow-2000 IPU Machine 是 Bow Pod 系統的構建塊。
它是基于與第二代 IPU-M2000 machine 同樣魯棒的系統架構,但是配備了四個強大的 Bow IPU 處理器,可提供 1.4 PetaFLOPS 的人工智能計算。
這么厲害的芯片,還不趕快拿來練練手?
近年來,語言模型的參數量不斷刷新。從驚艷四座的谷歌 BERT,到 OpenAI 的 GPT-3,再到微軟英偉達推出的威震天等等。
都對訓練時所需的計算性能提出了更大要求。
根據 Graphcore 公布的初始數據可以看出,這些模型在最新的硬件形態上都有很大的性能提升。
另外,在圖像方面,無論是典型的 CNN 網絡,還是近期比較熱門的 Vision Transformer 網絡,以及深層次的文本到圖片的網絡。
與上一代產品相比,Bow IPU 都有 30% 到 40% 的性能提升。
對于最先進的計算機視覺模型 EfficientNet,Bow Pod16 能夠提供可比 Nvidia DGX A100 系統 5 倍以上的性能,而價格只有它的一半,總體擁有成本優勢提升高達 10 倍。
下一步,超級智能 AI 計算機
Graphcore 今天還宣布了一件重大的事,正在開發一款超級智能 AI 計算機,要在 2024 年推出,售價 1.2 億美元。
我們知道,大腦是一個極其復雜的計算設備,在一個生物神經網絡系統中擁有大約 1000 億個神經元和超過 100 萬億個參數,它提供的計算水平是任何芯片計算機都無法比擬的。
而這款超級智能 AI 計算機 Good 將超越人類大腦的參數能力。
Good 計算機名字何來?是以計算機科學先驅 i.j. Jack Good 的名字命名。
Jack Good 在 1965 年的論文《關于第一臺超級智能機器的推測》中就描述了一種超越我們大腦能力的機器。
未來,它可以進行超過 10 Exa-Flops 的人工智能浮點計算,最高可達 4PB 的存儲,帶寬超過 10PB/秒。
Graphcore 的首席執行官 Graphcore 表示,「當我們創建 Graphcore 的時候,我們腦海中一直有一個想法,那就是建造一臺超智能計算機,它將超越人腦的能力,這就是我們現在正在努力做的事情。」
(邯鄲網站建設)